Claude Fable 5: What It Is, Benchmarks, Pricing, and Why It Matters
Claude Fable 5 brings Anthropic's Mythos-class capability to general availability, with top benchmark scores, strict safeguards, 1M-token context, and a new safety tradeoff for frontier AI users.
Claude Fable 5: What It Is, Benchmarks, Pricing, and Why It Matters
Claude Fable 5 is Anthropic's first generally available Mythos-class model. That is the important sentence.
Until now, Mythos-class Claude models were treated as controlled-access systems because their cyber and scientific capabilities crossed a risk threshold. With Fable 5, Anthropic is making that capability broadly available, but with a major constraint: safety classifiers route high-risk requests away from Fable 5 and toward Claude Opus 4.8.
The result is not just a bigger model launch. It is a release pattern for frontier models that are powerful enough to be useful in long-horizon coding, knowledge work, research, and automation, but sensitive enough that access policy becomes part of the product.
Source trail
- Anthropic announcement: Claude Fable 5 and Claude Mythos 5
- Claude API docs: Claude Fable 5 and Claude Mythos 5
- Claude models overview
- Anthropic: Expanding Project Glasswing
- GitHub: Claude Fable 5 in GitHub Copilot
- AWS: Claude Fable 5 on AWS
- Harvey: Fable 5 now available in Harvey
- TechCrunch coverage
- The Verge coverage
This article uses Anthropic's announcement and developer documentation as the factual base, and treats benchmark and customer claims as company-reported unless independently verified.
What Claude Fable 5 is
Claude Fable 5 is the public version of Anthropic's new Mythos-class capability tier. Anthropic describes Mythos-class as above Opus in capability. The same launch also introduced Claude Mythos 5, but Mythos 5 is not generally available. It is reserved for Project Glasswing partners and selected trusted-access users.
The practical distinction is simple:
| Model | Access | Safety posture | Best fit |
|---|---|---|---|
| Claude Fable 5 | Generally available | Includes classifiers and fallbacks | Advanced coding, long-horizon work, knowledge work, vision, enterprise automation |
| Claude Mythos 5 | Restricted | Same underlying model with safeguards lifted in some areas | Vetted cyberdefense and selected research programs |
| Claude Opus 4.8 | Generally available | Safer fallback model | Complex work where Fable is unavailable, unnecessary, or blocked by safeguards |
For developers, the model ID is claude-fable-5. Anthropic's docs list a 1M-token context window, up to 128k output tokens, always-on adaptive thinking, vision support, task budgets, compaction, the memory tool, and context-management features. Pricing is $10 per million input tokens and $50 per million output tokens.
Availability is broad at launch: Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry. GitHub also says Fable 5 is rolling into GitHub Copilot across VS Code, Visual Studio, Copilot CLI, cloud agent, JetBrains, Xcode, Eclipse, GitHub.com, and mobile surfaces for eligible plans. AWS has also announced Fable 5 availability on Amazon Bedrock and Claude Platform on AWS.
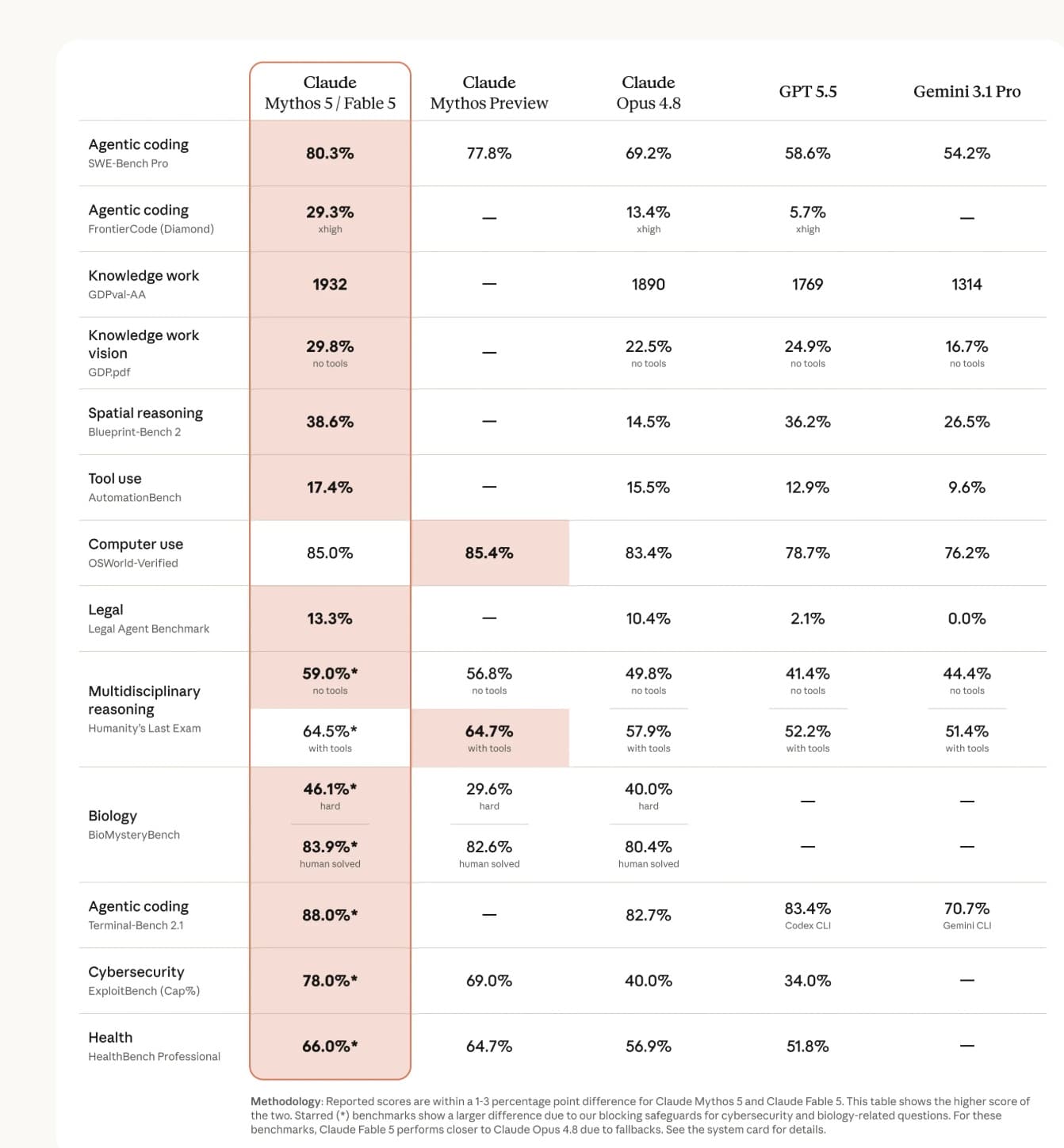
The benchmark picture
Anthropic's benchmark table shows Fable 5 leading most categories against Claude Mythos Preview, Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro.
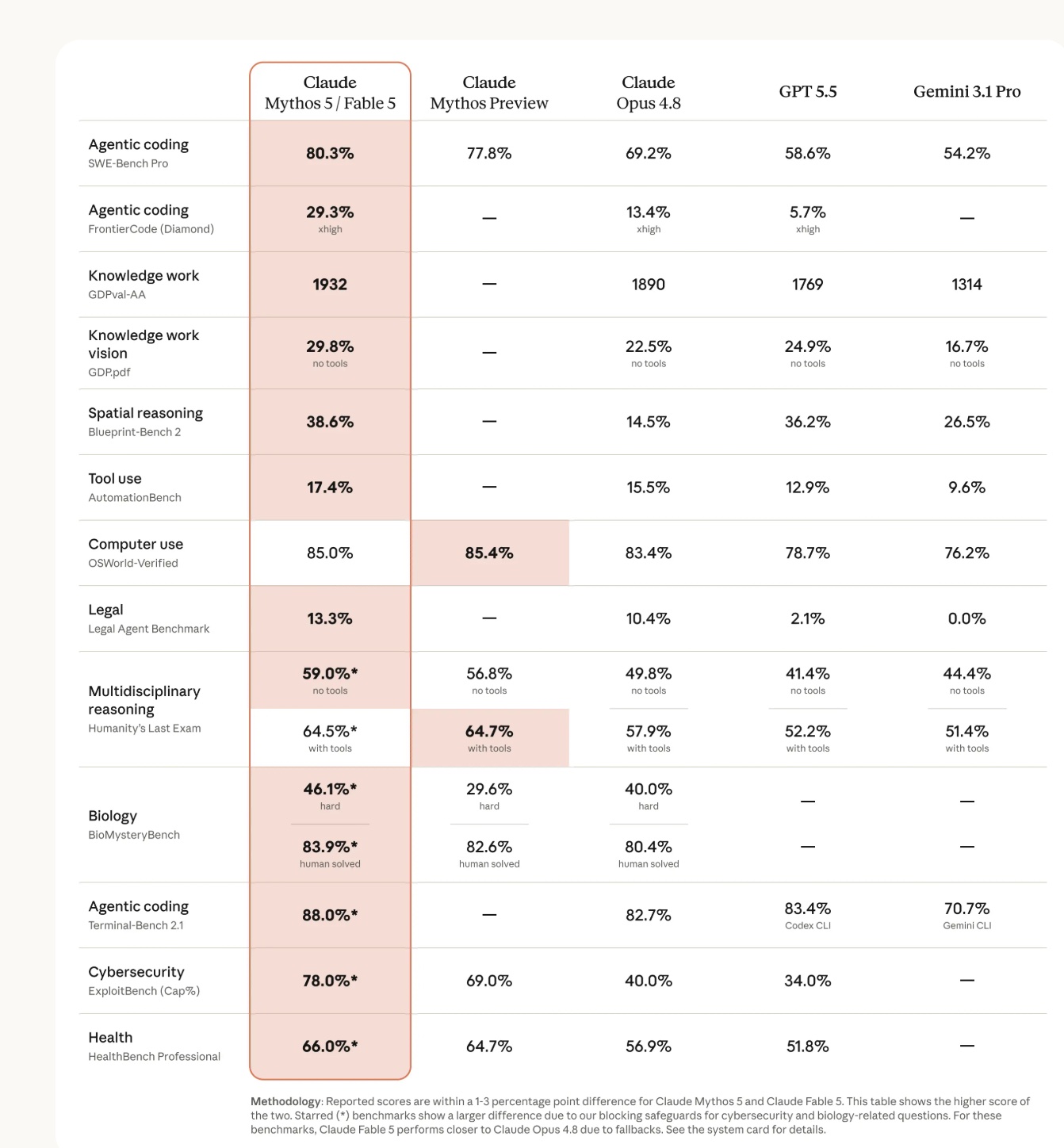
The headline scores from the attached benchmark image:
| Benchmark area | Benchmark | Claude Fable 5 / Mythos 5 | Closest listed competitor |
|---|---|---|---|
| Agentic coding | SWE-Bench Pro | 80.3% | Claude Mythos Preview at 77.8% |
| Agentic coding | FrontierCode Diamond | 29.3% | Claude Opus 4.8 at 13.4% |
| Knowledge work | GDPval-AA | 1932 | Claude Opus 4.8 at 1890 |
| Knowledge work vision | GDP.pdf, no tools | 29.8% | GPT-5.5 at 24.9% |
| Spatial reasoning | Blueprint-Bench 2 | 38.6% | GPT-5.5 at 36.2% |
| Tool use | AutomationBench | 17.4% | Claude Opus 4.8 at 15.5% |
| Computer use | OSWorld-Verified | 85.0% | Claude Mythos Preview at 85.4% |
| Legal | Legal Agent Benchmark | 13.3% | Claude Opus 4.8 at 10.4% |
| Multidisciplinary reasoning | Humanity's Last Exam, no tools | 59.0% | Claude Mythos Preview at 56.8% |
| Multidisciplinary reasoning | Humanity's Last Exam, with tools | 64.5% | Claude Mythos Preview at 64.7% |
| Biology | BioMysteryBench, hard | 46.1% | Claude Opus 4.8 at 40.0% |
| Biology | BioMysteryBench, human solved | 83.9% | Claude Mythos Preview at 82.6% |
| Agentic coding | Terminal-Bench 2.1 | 88.0% | GPT-5.5 Codex CLI at 83.4% |
| Cybersecurity | ExploitBench, capture percentage | 78.0% | Claude Mythos Preview at 69.0% |
| Health | HealthBench Professional | 66.0% | Claude Mythos Preview at 64.7% |
The pattern is clear: Fable 5's biggest advantage appears in long-horizon agentic work, difficult coding, cyber evaluation, and research-style tasks. It does not win every row. Mythos Preview is slightly ahead on OSWorld-Verified and tool-enabled Humanity's Last Exam. But Fable 5's average position is strong enough that the launch changes the top of the public model stack.
The methodology note matters. The attached image says Fable 5 and Mythos 5 scores are usually within 1 to 3 percentage points of each other, but starred benchmarks can differ more because Fable 5 has blocking safeguards for cyber and biology-related questions. In those cases, Fable may behave closer to Opus 4.8 because requests can fall back.
That means buyers should not read the table as "Fable is always Mythos." It is better read as: Fable is Mythos-class capability for normal use, with policy gates that intentionally reduce capability in risky domains.
Why the benchmarks matter
The strongest signal is not one score. It is the mix of score types.
SWE-Bench Pro and Terminal-Bench 2.1 point to coding agents that can operate across real repositories and terminal workflows. FrontierCode Diamond suggests performance on production-quality coding tasks, not just small algorithm puzzles. GDPval-AA, GDP.pdf, and Humanity's Last Exam point to knowledge work that requires document reasoning, visual interpretation, and tool-aware synthesis.
That combination matters because the market is moving from chatbots to agents. A frontier model is no longer judged only by whether it can answer questions. It is judged by whether it can sustain a task, use tools, recover from failure, and keep a coherent plan over a long context.
Anthropic is explicitly positioning Fable 5 for that kind of work. The company says the model's lead grows as tasks become longer and more complex. Early customer claims in the launch post point to codebase migrations, finance analysis, spreadsheet work, legal redlining, physics research, and app prototyping.
Those are exactly the workflows where small differences in planning quality compound. A model that is slightly better at every step can become much better over a 40-step task.
The safety layer is part of the product
The core tradeoff in Fable 5 is not price. It is capability versus controlled access.
Anthropic says Fable 5 includes classifiers for cybersecurity, biology and chemistry, and distillation. When those classifiers trigger, the request is handled by Claude Opus 4.8 instead of Fable 5. Anthropic says more than 95% of Fable sessions do not involve fallback, but also says the safeguards are tuned conservatively and may catch benign requests.
That creates a new user experience pattern:
- For most ordinary work, users get the full Fable 5 experience.
- For sensitive domains, the model may transparently fall back to Opus 4.8.
- For developers, refusals and fallback behavior must be handled as normal API paths, not edge-case errors.
The API docs also note a 30-day data-retention requirement for Fable 5 and Mythos 5 traffic. Anthropic says this retention supports safety monitoring and jailbreak detection, and that the data is not used to train new Claude models. Still, this is a real procurement issue. Some customers that require zero data retention will need to review whether Fable 5 fits their data policy.
What changed for builders
For developers, the immediate question is not "Should I replace every model with Fable 5?" The better question is where Fable 5's incremental capability justifies its higher cost and policy requirements.
Good candidates:
- Large codebase refactors
- Agentic coding in existing repositories
- Multi-file debugging and migration work
- Long document analysis
- Finance, legal, and research workflows with dense context
- Vision-heavy document and screenshot understanding
- High-value workflows where fewer turns are worth more than cheaper tokens
Weak candidates:
- Simple classification
- Routine summarization
- Low-risk support macros
- Short extraction tasks
- High-volume workloads where Haiku, Sonnet, or cheaper models already meet quality targets
- Workloads that require zero data retention
Fable 5 is expensive relative to Opus 4.8, and much more expensive than smaller models. But if it completes a task in fewer attempts, uses fewer retries, and reduces human correction, the unit economics may still work. Token price alone is the wrong metric. Cost per completed workflow is the metric that matters.
What changed for enterprises
Enterprise buyers now have to evaluate frontier models on four dimensions, not one:
| Dimension | Question to ask |
|---|---|
| Capability | Does it beat the current model on our actual workflow, not just public benchmarks? |
| Policy | What requests are blocked, refused, or routed to fallback? |
| Data | Is 30-day retention acceptable for this use case? |
| Economics | Does the model reduce total cost per resolved task despite higher token prices? |
This launch also pressures AI governance teams. Fable 5 is powerful enough that "we allow Claude" is no longer a precise policy. Companies will need model-level permissions. Some teams may allow Sonnet and Opus for broad use, but restrict Fable 5 to approved workflows because of data retention, cost, or sensitive-domain behavior.
That is not a weakness. It is how serious AI deployment should work. More capable models need clearer operating boundaries.
The competitive read
The benchmark table places Fable 5 ahead of GPT-5.5 and Gemini 3.1 Pro in many of the attached categories. The bigger competitive move is distribution.
Anthropic is not only launching through Claude. Fable 5 is showing up in the Claude API, AWS, Bedrock, Vertex AI, Microsoft Foundry, GitHub Copilot, and vertical products like Harvey. That matters because frontier model competition is increasingly decided by where the model can be used safely inside existing workflows.
GitHub Copilot availability gives Fable 5 a direct path into developer work. AWS and Bedrock availability give enterprise cloud teams a procurement and governance path. Harvey's announcement matters for legal workflows because it shows vertical AI products are already trying to turn Fable 5 into domain-specific execution.
The model race is now a distribution race, a policy race, and an evaluation race.
Bottom line
Claude Fable 5 is Anthropic's strongest public model and the first broad release of Mythos-class capability. The benchmark table shows clear leadership in agentic coding, long-context knowledge work, vision-heavy reasoning, legal tasks, cyber evaluation, biology, and health benchmarks.
But the release should not be reduced to "better benchmark scores." The important shift is that Anthropic is packaging a restricted frontier capability into a public product by adding classifiers, fallback behavior, usage-policy controls, and 30-day safety retention.
For builders, Fable 5 is worth testing on tasks where long-horizon reliability matters more than raw token cost. For enterprises, it should be evaluated as a high-capability model with explicit governance requirements. For the market, it signals that the next phase of AI competition will be about controlled deployment of models that are powerful enough to need real access design.
The practical advice: benchmark it on your hardest workflow, measure completed-task cost, inspect fallback behavior, and check data-retention fit before rolling it out broadly.