Autonomous Network Incident Resolution Shows Where Agentic AI Can Earn Real Trust
A new agentic AI network-operations paper reports high autonomous resolution rates and offers a practical blueprint for safe AI agents.
The most credible AI agent may not be the one that books a meeting or writes a memo. It may be the one that fixes a familiar network incident, proves the fix worked, and rolls back when it does not.
A June 8 arXiv paper titled Autonomous Incident Resolution at Hyperscale describes a multi-agent architecture for large-scale network operations. The author reports production deployment at a major cloud provider and autonomous resolution rates exceeding 90 percent for common incident categories, with layered authorization, structured runbooks, skills-based tool invocation, and closed-loop verification.
For readers tracking latest AI news and Artificial Intelligence News, the importance is not that another AI headline appeared. The importance is that this story exposes a concrete operating constraint: the people buying, regulating, deploying, or building AI systems now have to make decisions before the infrastructure around those systems is mature. That is the connective tissue between model releases, agentic AI, AI training, AI tools, and enterprise governance in 2026.
This ShShell analysis is source-grounded but not a wire rewrite. It separates what the cited reports say, what can be inferred from the technical or commercial mechanism, and what remains uncertain. The goal is to help builders, buyers, researchers, and operators understand how this specific event changes the next set of decisions.
What changed on June 12
Autonomous incident resolution sounds like an operations fantasy until network teams face the arithmetic. Hyperscale networks generate more alerts, dependencies, configuration states, and failure modes than humans can triage by hand. A recent arXiv paper describes an agentic AI architecture for network operations that reportedly exceeds 90 percent autonomous resolution for common incident categories at a major cloud provider. That claim deserves careful reading, but the architecture itself is the news: agents are moving from demo workflows into reliability engineering.
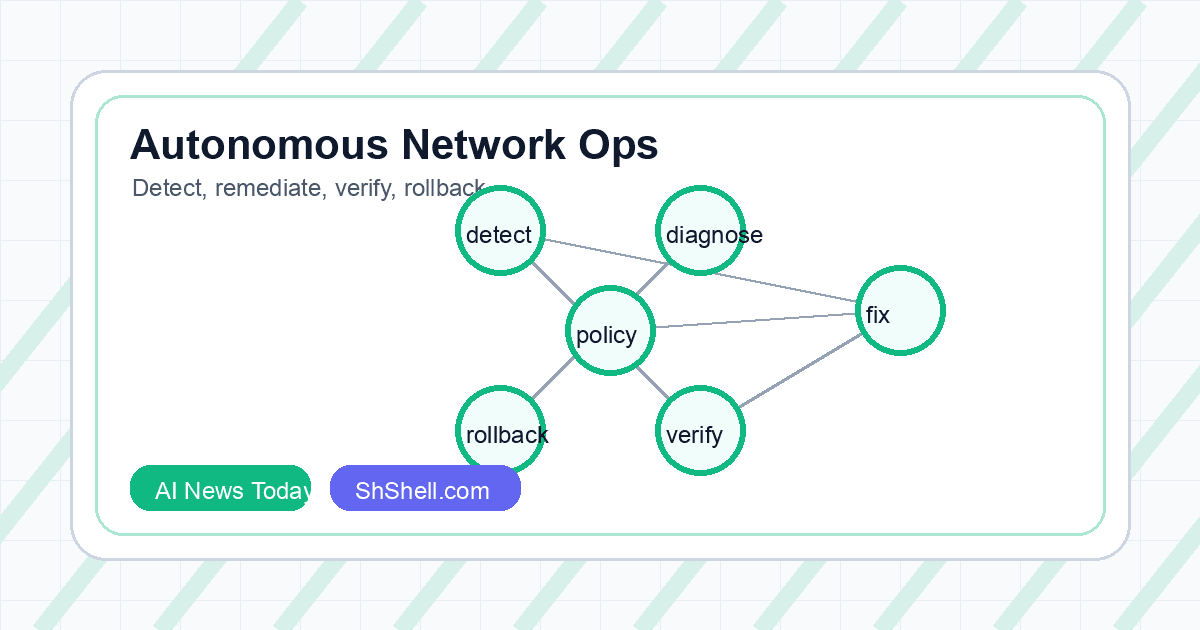
The mechanism is bounded autonomy. The paper describes specialized agents for detection, diagnosis, remediation, verification, and rollback. Instead of asking one large language model to be an all-purpose operator, the system decomposes incident response into role-specific agents with tool access, runbook knowledge, authorization boundaries, and closed-loop verification. That is what makes the report relevant to enterprise AI: the agent is not trusted because it sounds confident. It is trusted only inside a scaffold that limits actions and verifies outcomes.
For builders, the useful lesson is that agentic AI in operations should start with runbooks, not imagination. The strongest candidates are high-frequency incidents with known signatures, well-defined remediation steps, measurable recovery conditions, and reversible changes. A routing flap, certificate expiry pattern, exhausted quota, or repeated configuration drift can be safer to automate than a rare ambiguous outage. The agent earns autonomy by proving it can resolve repeatable incidents within strict guardrails.
For operators, the risk is silent blast radius. A human can make a bad change slowly; an agent can make one quickly and repeatedly. That is why progressive autonomy matters. Read-only diagnosis, suggested remediation, supervised execution, limited auto-remediation, and full autonomous rollback should be separate maturity levels. The paper’s emphasis on layered authorization and rollback is not a footnote. It is the difference between an AI assistant and an outage amplifier.
The mechanism behind the headline
Autonomous incident resolution sounds like an operations fantasy until network teams face the arithmetic. Hyperscale networks generate more alerts, dependencies, configuration states, and failure modes than humans can triage by hand. A recent arXiv paper describes an agentic AI architecture for network operations that reportedly exceeds 90 percent autonomous resolution for common incident categories at a major cloud provider. That claim deserves careful reading, but the architecture itself is the news: agents are moving from demo workflows into reliability engineering.
The mechanism is bounded autonomy. The paper describes specialized agents for detection, diagnosis, remediation, verification, and rollback. Instead of asking one large language model to be an all-purpose operator, the system decomposes incident response into role-specific agents with tool access, runbook knowledge, authorization boundaries, and closed-loop verification. That is what makes the report relevant to enterprise AI: the agent is not trusted because it sounds confident. It is trusted only inside a scaffold that limits actions and verifies outcomes.
For builders, the useful lesson is that agentic AI in operations should start with runbooks, not imagination. The strongest candidates are high-frequency incidents with known signatures, well-defined remediation steps, measurable recovery conditions, and reversible changes. A routing flap, certificate expiry pattern, exhausted quota, or repeated configuration drift can be safer to automate than a rare ambiguous outage. The agent earns autonomy by proving it can resolve repeatable incidents within strict guardrails.
For operators, the risk is silent blast radius. A human can make a bad change slowly; an agent can make one quickly and repeatedly. That is why progressive autonomy matters. Read-only diagnosis, suggested remediation, supervised execution, limited auto-remediation, and full autonomous rollback should be separate maturity levels. The paper’s emphasis on layered authorization and rollback is not a footnote. It is the difference between an AI assistant and an outage amplifier.
flowchart TD
A[Network alert] --> B[Detection agent]
B --> C[Diagnosis agent]
C --> D[Runbook retrieval]
D --> E{Authorization boundary}
E --> F[Remediation agent]
F --> G[Verification agent]
G --> H{Recovered}
H --> I[Close incident]
H --> J[Rollback and escalate]
Why this matters for builders and AI operators
Autonomous incident resolution sounds like an operations fantasy until network teams face the arithmetic. Hyperscale networks generate more alerts, dependencies, configuration states, and failure modes than humans can triage by hand. A recent arXiv paper describes an agentic AI architecture for network operations that reportedly exceeds 90 percent autonomous resolution for common incident categories at a major cloud provider. That claim deserves careful reading, but the architecture itself is the news: agents are moving from demo workflows into reliability engineering.
The mechanism is bounded autonomy. The paper describes specialized agents for detection, diagnosis, remediation, verification, and rollback. Instead of asking one large language model to be an all-purpose operator, the system decomposes incident response into role-specific agents with tool access, runbook knowledge, authorization boundaries, and closed-loop verification. That is what makes the report relevant to enterprise AI: the agent is not trusted because it sounds confident. It is trusted only inside a scaffold that limits actions and verifies outcomes.
For builders, the useful lesson is that agentic AI in operations should start with runbooks, not imagination. The strongest candidates are high-frequency incidents with known signatures, well-defined remediation steps, measurable recovery conditions, and reversible changes. A routing flap, certificate expiry pattern, exhausted quota, or repeated configuration drift can be safer to automate than a rare ambiguous outage. The agent earns autonomy by proving it can resolve repeatable incidents within strict guardrails.
For operators, the risk is silent blast radius. A human can make a bad change slowly; an agent can make one quickly and repeatedly. That is why progressive autonomy matters. Read-only diagnosis, suggested remediation, supervised execution, limited auto-remediation, and full autonomous rollback should be separate maturity levels. The paper’s emphasis on layered authorization and rollback is not a footnote. It is the difference between an AI assistant and an outage amplifier.
| Autonomy level | Agent permission | Best workload | Required safety check |
|---|---|---|---|
| Advisory | Read logs and suggest fix | New incident classes | Human approval |
| Supervised | Prepare command for review | Known but risky fixes | Change window approval |
| Limited auto | Execute bounded fix | Common reversible issues | Automated verification |
| Full bounded | Fix and rollback | High-volume routine incidents | Policy plus rollback proof |
The business pressure underneath the AI News Today cycle
Autonomous incident resolution sounds like an operations fantasy until network teams face the arithmetic. Hyperscale networks generate more alerts, dependencies, configuration states, and failure modes than humans can triage by hand. A recent arXiv paper describes an agentic AI architecture for network operations that reportedly exceeds 90 percent autonomous resolution for common incident categories at a major cloud provider. That claim deserves careful reading, but the architecture itself is the news: agents are moving from demo workflows into reliability engineering.
The mechanism is bounded autonomy. The paper describes specialized agents for detection, diagnosis, remediation, verification, and rollback. Instead of asking one large language model to be an all-purpose operator, the system decomposes incident response into role-specific agents with tool access, runbook knowledge, authorization boundaries, and closed-loop verification. That is what makes the report relevant to enterprise AI: the agent is not trusted because it sounds confident. It is trusted only inside a scaffold that limits actions and verifies outcomes.
For builders, the useful lesson is that agentic AI in operations should start with runbooks, not imagination. The strongest candidates are high-frequency incidents with known signatures, well-defined remediation steps, measurable recovery conditions, and reversible changes. A routing flap, certificate expiry pattern, exhausted quota, or repeated configuration drift can be safer to automate than a rare ambiguous outage. The agent earns autonomy by proving it can resolve repeatable incidents within strict guardrails.
For operators, the risk is silent blast radius. A human can make a bad change slowly; an agent can make one quickly and repeatedly. That is why progressive autonomy matters. Read-only diagnosis, suggested remediation, supervised execution, limited auto-remediation, and full autonomous rollback should be separate maturity levels. The paper’s emphasis on layered authorization and rollback is not a footnote. It is the difference between an AI assistant and an outage amplifier.
The risks that are still unresolved
Autonomous incident resolution sounds like an operations fantasy until network teams face the arithmetic. Hyperscale networks generate more alerts, dependencies, configuration states, and failure modes than humans can triage by hand. A recent arXiv paper describes an agentic AI architecture for network operations that reportedly exceeds 90 percent autonomous resolution for common incident categories at a major cloud provider. That claim deserves careful reading, but the architecture itself is the news: agents are moving from demo workflows into reliability engineering.
The mechanism is bounded autonomy. The paper describes specialized agents for detection, diagnosis, remediation, verification, and rollback. Instead of asking one large language model to be an all-purpose operator, the system decomposes incident response into role-specific agents with tool access, runbook knowledge, authorization boundaries, and closed-loop verification. That is what makes the report relevant to enterprise AI: the agent is not trusted because it sounds confident. It is trusted only inside a scaffold that limits actions and verifies outcomes.
For builders, the useful lesson is that agentic AI in operations should start with runbooks, not imagination. The strongest candidates are high-frequency incidents with known signatures, well-defined remediation steps, measurable recovery conditions, and reversible changes. A routing flap, certificate expiry pattern, exhausted quota, or repeated configuration drift can be safer to automate than a rare ambiguous outage. The agent earns autonomy by proving it can resolve repeatable incidents within strict guardrails.
For operators, the risk is silent blast radius. A human can make a bad change slowly; an agent can make one quickly and repeatedly. That is why progressive autonomy matters. Read-only diagnosis, suggested remediation, supervised execution, limited auto-remediation, and full autonomous rollback should be separate maturity levels. The paper’s emphasis on layered authorization and rollback is not a footnote. It is the difference between an AI assistant and an outage amplifier.
What to watch next
Autonomous incident resolution sounds like an operations fantasy until network teams face the arithmetic. Hyperscale networks generate more alerts, dependencies, configuration states, and failure modes than humans can triage by hand. A recent arXiv paper describes an agentic AI architecture for network operations that reportedly exceeds 90 percent autonomous resolution for common incident categories at a major cloud provider. That claim deserves careful reading, but the architecture itself is the news: agents are moving from demo workflows into reliability engineering.
The mechanism is bounded autonomy. The paper describes specialized agents for detection, diagnosis, remediation, verification, and rollback. Instead of asking one large language model to be an all-purpose operator, the system decomposes incident response into role-specific agents with tool access, runbook knowledge, authorization boundaries, and closed-loop verification. That is what makes the report relevant to enterprise AI: the agent is not trusted because it sounds confident. It is trusted only inside a scaffold that limits actions and verifies outcomes.
For builders, the useful lesson is that agentic AI in operations should start with runbooks, not imagination. The strongest candidates are high-frequency incidents with known signatures, well-defined remediation steps, measurable recovery conditions, and reversible changes. A routing flap, certificate expiry pattern, exhausted quota, or repeated configuration drift can be safer to automate than a rare ambiguous outage. The agent earns autonomy by proving it can resolve repeatable incidents within strict guardrails.
For operators, the risk is silent blast radius. A human can make a bad change slowly; an agent can make one quickly and repeatedly. That is why progressive autonomy matters. Read-only diagnosis, suggested remediation, supervised execution, limited auto-remediation, and full autonomous rollback should be separate maturity levels. The paper’s emphasis on layered authorization and rollback is not a footnote. It is the difference between an AI assistant and an outage amplifier.
The operator playbook for safe network agents
Network teams should begin with incidents that already have disciplined runbooks. A safe candidate has a clear trigger, known diagnostic commands, bounded remediation, a measurable success condition, and a rollback path. Examples include stale route advertisements, expired certificates, exhausted connection pools, predictable quota failures, and configuration drift where the correct state is known. These are not glamorous, but they are where autonomous incident resolution can earn trust without asking the agent to improvise during a novel crisis.
The second design principle is read-first autonomy. Before an agent can change a network, it should prove it can read telemetry, correlate symptoms, identify likely causes, and produce a remediation plan that humans agree with. That evidence should be logged. Over time, teams can compare agent recommendations to human actions and promote only the incident classes where the agent repeatedly matches or improves operator judgment. Autonomy should be earned by incident class, not granted globally because a demo looked impressive.
The third design principle is tool minimalism. A remediation agent does not need every credential. It needs the narrow tools required for the approved fix. If it handles certificate renewal, give it certificate and deployment tools, not broad network-administrator privileges. If it resets a service, scope the action to known hosts. If it edits routing policy, require a pre-change simulation and rollback snapshot. The smaller the tool surface, the easier it is to reason about blast radius.
The fourth design principle is verification as a separate agent role. The same agent that made a change should not be the only judge of whether the change worked. A verification agent can check independent telemetry, synthetic probes, error budgets, and customer-impact metrics. If recovery does not match the runbook’s success condition, rollback and escalation should be automatic. This separation mirrors good human operations practice: the person making a risky change should not be the only source of truth about recovery.
For enterprise AI leaders, the June arXiv paper is useful because it reframes agents as operational systems, not personalities. Trust comes from decomposition, authorization, measurement, and rollback. That is the same pattern buyers should demand from AI agents in finance, security, customer operations, and software delivery.
What teams should do next quarter
The next practical move is to turn the news event into a checklist with owners. Assign one person to map the affected workflows, one person to verify vendor claims, one person to define the risk thresholds, and one person to measure outcomes after deployment. That sounds mundane, but most AI programs fail at exactly this handoff. They discuss strategy at a high level, buy a tool, and then discover that nobody owns the operational questions raised by the tool.
The checklist should be specific enough to change behavior. Which data can enter the system? Which actions require human approval? Which logs are retained? Which model or agent is allowed to call which tool? Which failure conditions trigger rollback? Which costs count as success costs rather than experimentation costs? If the team cannot answer these questions in writing, it is not ready for broad rollout.
Teams should also create a small measurement packet for executives. It should include quality, cost, latency, risk exceptions, human review load, and incidents avoided or created. AI News Today headlines often make adoption feel binary: move fast or fall behind. Production reality is more measured. The winners will be the teams that can show where an AI system works, where it should stay supervised, where it is too expensive, and where the risk boundary is still unclear.
For ShShell readers learning AI from a builder’s perspective, this is the habit to develop: convert every major Artificial Intelligence News story into architecture, controls, and metrics. The headline tells you what changed. The operating model tells you whether that change should alter your roadmap.
The immediate discipline is simple: do not promote autonomy faster than observability, rollback, and ownership can support it.
That discipline also protects budgets. A team that cannot observe an agent cannot price it, secure it, or explain it after a failure. The responsible path is not to reject agentic AI. It is to make every additional permission earn its place through measured reliability, bounded scope, and clear accountability.
The reader decision hidden inside the headline
The useful way to read this story is as a decision prompt, not as passive news. Ask what would have to be true for your team to act differently tomorrow. If the answer is better vendor visibility, put that into procurement. If the answer is safer tool permissions, put that into engineering design. If the answer is clearer measurement, put that into dashboards before the next rollout. AI adoption becomes less speculative when every headline is converted into an operational question with a named owner.
The second decision is timing. Some teams should move immediately because the risk or opportunity touches an active deployment. Others should watch for one more signal: a regulation, a pricing change, a model update, an audit report, or a production case study. Both responses can be rational. The mistake is to treat latest AI news as entertainment while the underlying architecture, cost model, or governance expectation changes under your feet.
For builders, this is also a prompt engineering lesson. Good prompts define the task, context, constraints, and acceptance criteria. Good AI strategy does the same. Define the task the AI system is allowed to perform, the context it may use, the constraints it must obey, and the evidence required before output becomes action.
Sources used for this article
Author note
Sudeep Devkota is an AI architect and ShShell editor focused on agentic systems, enterprise AI strategy, and production-grade AI operations.