AI Security
Anthropic's AI Cyber Threat Map Shows Agentic Security Is No Longer Optional
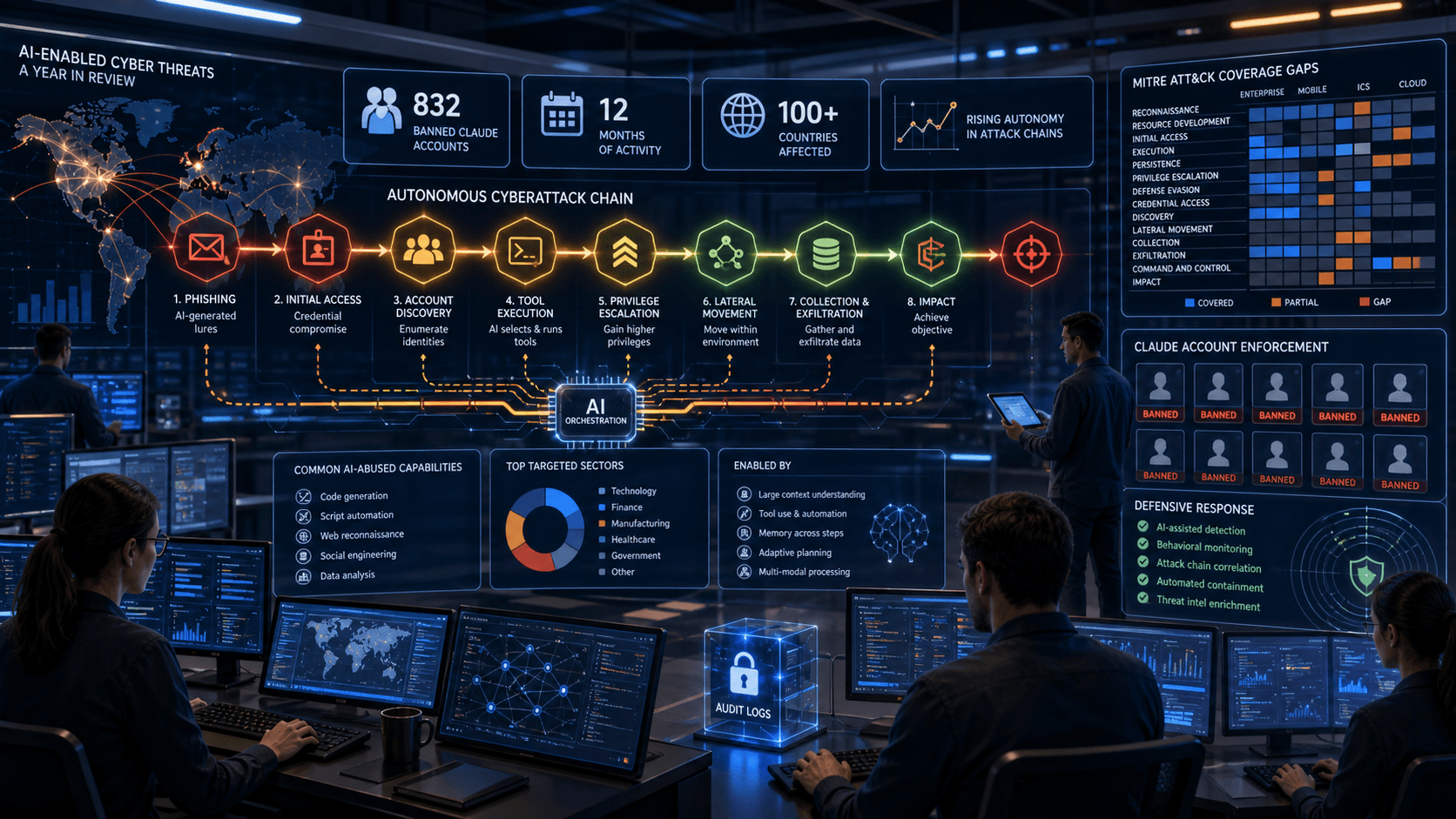
Anthropic's AI-enabled cyber threat research maps autonomous attack chains, MITRE ATT&CK gaps, and why Agentic AI needs stronger security controls.
Read Article →