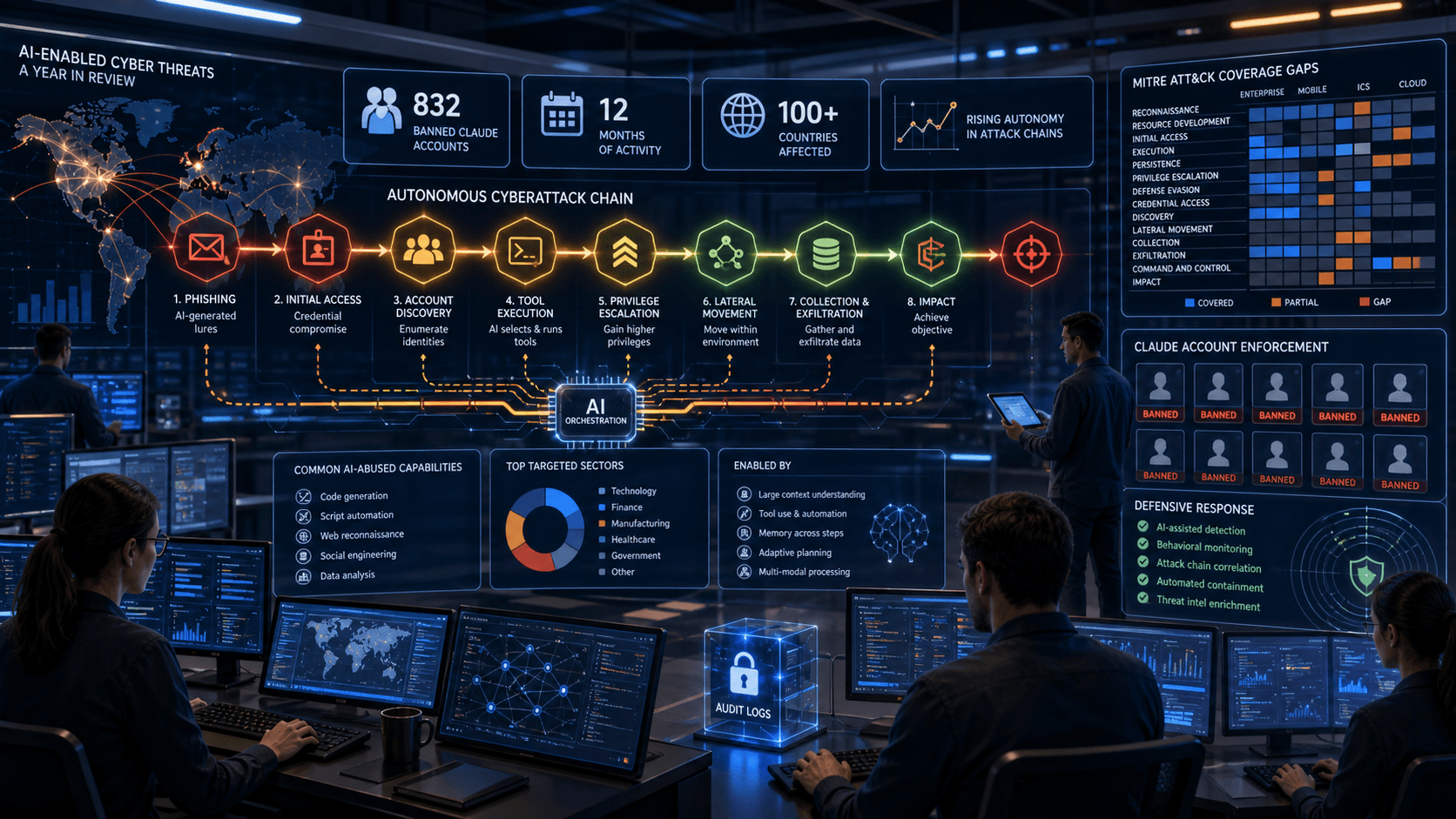
Anthropic's AI Cyber Threat Map Shows Agentic Security Is No Longer Optional
Anthropic's AI-enabled cyber threat research maps autonomous attack chains, MITRE ATT&CK gaps, and why Agentic AI needs stronger security controls.
Anthropic's AI Cyber Threat Map Shows Agentic Security Is No Longer Optional
Anthropic's cyber threat research is useful because it does not treat malicious AI use as a future thought experiment. It describes a more immediate problem: attackers are already trying to fold large language models into reconnaissance, scripting, credential targeting, vulnerability discovery, phishing, and operational planning. That puts Agentic AI inside the same threat models that security teams use for cloud infrastructure, identity, code repositories, and endpoint fleets.
The practical takeaway is blunt. If an AI system can search, reason, write code, use tools, translate language, and remember context across steps, then security teams cannot evaluate it as a chatbot. They have to evaluate it as a workflow engine. Anthropic's mapping to MITRE ATT&CK matters because it gives defenders a shared language for describing AI-assisted behavior before the industry invents five incompatible vocabularies for the same attack chain.
Source trail
- Anthropic research on AI-enabled cyber threats and MITRE ATT&CK
- Anthropic coordinated vulnerability disclosure dashboard
- MITRE ATT&CK framework
- The Hacker News coverage of Anthropic cyber threat findings
- CYBERScoop coverage of Anthropic and MITRE mapping
This article uses those sources as the factual base and adds ShShell analysis for builders, security operators, AI governance teams, and readers tracking latest AI news. Anthropic's examples should be read as a risk map, not as a claim that every attacker now runs fully autonomous hacking agents.
What Anthropic actually put on the table
Anthropic's report describes AI-enabled cyber threat activity and maps observed or plausible behaviors to MITRE ATT&CK techniques. That framing is important. MITRE ATT&CK is the common taxonomy many defenders already use to describe tactics such as reconnaissance, initial access, execution, persistence, credential access, discovery, lateral movement, collection, command and control, and exfiltration. By placing AI-assisted activity into that framework, Anthropic is arguing that model misuse is not a separate security universe. It is a capability layer that can accelerate existing intrusion paths.
The most concrete part of the story is not "AI can hack." That sentence is too vague to help anyone. The concrete issue is task compression. A large language model can help an attacker draft phishing lures, translate them, adapt tone to a target, write proof-of-concept scripts, debug broken exploit code, summarize documentation, classify leaked data, and generate next-step plans from error messages. None of those tasks guarantees compromise. Together, they reduce friction.
That is why this belongs in AI News Today rather than only in a security bulletin. AI tools are moving from answer boxes into operational systems. A coding assistant, an ai search workflow, an agentic browser, and a security copilot all share the same underlying question: what can the model do after the prompt. Anthropic's report forces that question into the cyber domain, where vague product language is not good enough.
The cyber kill chain is becoming a model-assisted workflow
The old mental model treats an attacker as a person who uses software. The new mental model treats the attacker as a person plus a stack of AI-enabled helpers. The human still chooses targets and objectives. The model can help with the tedious intermediate work: gathering context, generating candidate commands, translating logs, proposing scripts, ranking vulnerabilities, and making social engineering cheaper.
graph TD
Target[Target selection]
Recon[AI-assisted reconnaissance]
Lure[Localized phishing or pretext]
Script[Generated scripts and exploit drafts]
Debug[Model-assisted debugging]
Access[Credential or system access attempt]
Post[Discovery, collection, and reporting]
Defend[Defender detection and response]
Target --> Recon
Recon --> Lure
Recon --> Script
Script --> Debug
Debug --> Access
Lure --> Access
Access --> Post
Recon --> Defend
Script --> Defend
Access --> Defend
This diagram is intentionally about workflow, not model magic. The security risk is not that a model independently invents every step of an intrusion. The risk is that the model makes each small step easier, faster, and more accessible. A less skilled attacker can ask better questions. A skilled attacker can move faster. A language barrier becomes less meaningful. A defensive analyst can be flooded with more customized attempts.
For defenders, the same capability can be used in reverse. AI agents can summarize alerts, correlate evidence, generate detection logic, triage vulnerability reports, and prepare incident timelines. That creates a race around controlled tool use. The side with better logs, permissions, evaluations, and escalation rules gets more value from AI. The side with weak controls gets a larger attack surface.
Why MITRE ATT&CK is the right lens
Security teams already use MITRE ATT&CK to avoid vague phrases like "advanced attack" or "AI-powered intrusion." A mapped technique can drive detections, tabletop exercises, logging requirements, and response playbooks. Anthropic's move matters because it tries to attach AI-enabled behavior to this existing operational language.
That helps in three ways. First, it keeps security teams from treating AI misuse as a mysterious new category that requires a completely separate risk program. Second, it makes AI governance more concrete. A policy can say that model-assisted credential discovery, phishing generation, malware modification, or vulnerability exploitation belongs in the same control set as the non-AI version. Third, it lets teams compare model-enabled risk against existing telemetry. If the organization cannot detect the underlying ATT&CK technique today, it will not detect the AI-assisted variant tomorrow.
The gap is that MITRE ATT&CK describes adversary behavior, while agentic systems also create platform behavior. An enterprise AI assistant may retrieve documents, call APIs, write code, open tickets, or produce summaries that influence decisions. That activity has to be logged with the same seriousness as human activity. Otherwise defenders may see the outcome but miss the model's contribution.
Who is affected first
The first affected group is security operations teams. They need to decide whether their current alerting can distinguish ordinary automation from suspicious AI-enabled activity. For example, a model-assisted attacker may generate many variants of a phishing message, run faster reconnaissance, or ask a model to adapt code based on endpoint errors. The signals may look like volume, variation, or timing rather than a brand-new artifact.
The second group is application security and product teams. Any company exposing AI agents to internal tools has to define what the agent can read, write, execute, and remember. If a support agent can access customer records, a coding agent can modify repositories, or a research agent can browse internal documents, then prompt injection and tool abuse become security issues, not only quality issues.
The third group is AI vendors. Anthropic is implicitly arguing that frontier model providers need abuse monitoring, account enforcement, vulnerability disclosure channels, red-team programs, and clear policy boundaries. Buyers should ask for those details. It is not enough to say a model is safer. The vendor should be able to explain how misuse is detected, how accounts are handled, what categories are restricted, and how vulnerability reports move through a coordinated disclosure process.
The important distinction: assistance is not autonomy
The strongest version of this story is not "AI agents are now autonomous hackers." That overstates the evidence and makes defenders less precise. The more accurate statement is that AI can assist parts of the attack lifecycle, and some of those parts are exactly where time, language, and expertise used to slow attackers down.
That distinction matters for defensive planning. If a team believes the threat is a fully autonomous hacker, it may chase speculative controls. If it understands the threat as model-assisted task acceleration, it can improve detection where the pressure will actually show up: identity abuse, phishing volume, script variation, vulnerability triage noise, suspicious tool calls, data staging, and unusual access paths.
It also matters for AI training. People learning prompt engineering or ai agents should not treat security as a final checkbox. The prompt is part of the control plane. A prompt can ask for code, but the system decides whether code execution is allowed. A prompt can ask for sensitive data, but retrieval permissions decide what comes back. A prompt can ask for a next step, but the product must decide whether the next step is advice, a draft, or an action.
What changed for enterprise security teams
Enterprise teams should now treat agent traces as security telemetry. That includes the user's prompt, the model's plan, retrieved documents, tool calls, API responses, generated code, execution attempts, human approvals, and final output. If a model helps perform a risky action, the action should be attributable. The organization needs to know who invoked the workflow, which model ran, which tools were used, what data was accessed, and what the model suggested.
This is not just for compliance. It is how teams debug incidents. Suppose an internal agent accidentally exposes a sensitive document in a summary. Without trace data, the team can only inspect the final answer. With trace data, it can see which retrieval source was used, whether permissions were respected, whether the prompt asked for restricted information, and whether the model ignored a policy instruction.
Security teams should also create AI-specific abuse tests. A normal penetration test may check endpoints and credentials. An AI workflow test should check prompt injection, tool permission boundaries, retrieval leakage, unsafe code generation, refusal behavior, logging completeness, and human approval gates. The right question is not "can the model be tricked" in the abstract. The right question is "what damage can a tricked model cause inside this workflow."
Controls that should move from optional to required
| Control | Why Anthropic's mapping makes it urgent | What good looks like |
|---|---|---|
| Tool permissions | AI-assisted attacks benefit when tools are broad and unlogged. | Least-privilege tool access, scoped tokens, and explicit approval for state-changing actions. |
| Agent traces | Defenders need to see how a model moved from prompt to action. | Prompt, retrieval, tool call, response, and reviewer logs retained with incident-searchable metadata. |
| Abuse monitoring | Model providers and enterprises need visibility into suspicious patterns. | Detection for phishing generation, exploit assistance, credential targeting, and unusual automation bursts. |
| Prompt-injection tests | AI agents can be manipulated through retrieved content or user input. | Adversarial test sets that include malicious documents, links, instructions, and tool requests. |
| Human review gates | Models can accelerate risky tasks before humans notice. | Confirmation for external messages, code execution, data export, and privilege-impacting actions. |
These controls are not glamorous, but they decide whether Agentic AI becomes manageable infrastructure or an untracked side channel.
What builders should do differently this week
Builders should start by inventorying every AI workflow that can touch a tool. A pure drafting assistant is one category. An agent that can browse internal documents is another. An agent that can write tickets, update records, generate code, or call security tools is a higher-risk category. Put each workflow in a simple table with data access, tool access, user role, output destination, approval requirement, and logging status.
Next, build one misuse scenario per workflow. For a coding agent, test whether it will generate unsafe dependency changes or execute commands without sufficient review. For an ai search agent, test whether a malicious document can influence the answer. For a customer support agent, test whether it can reveal private records through a crafted request. For a security copilot, test whether it can produce exploit steps beyond the organization's policy.
Then connect the result to your existing security program. If an AI workflow can produce code, it belongs near secure software development controls. If it can access customer data, it belongs near privacy and data governance. If it can trigger operational actions, it belongs near change management. Treating AI as a separate innovation lab issue is how risk escapes ownership.
What buyers should ask Anthropic and every other AI vendor
The buyer questions are now specific. How does the vendor detect abusive cyber use. What categories are blocked. How are borderline requests reviewed. Are enterprise prompts used for training. How are tool calls logged. Can customers export traces. What vulnerability disclosure process exists. How fast are model behavior changes communicated. Does the vendor provide red-team findings, safety evaluations, and abuse trend summaries in a format security teams can actually use.
Buyers should also ask how model updates affect risk. A model that becomes better at coding may also become better at writing exploit-like code. A model that becomes better at multilingual reasoning may also make localized social engineering easier. Improvement is not bad. Unreviewed improvement is the issue. Security teams need change notifications and regression tests just as they do for other critical software.
Cost and latency matter too, but they should not dominate the first conversation. A cheaper agent that cannot be audited is expensive after an incident. A fast agent that can call sensitive tools without review is a liability. The right enterprise procurement question is not whether the model is impressive. It is whether the full system can be governed.
Why this is also a defender opportunity
The same model capabilities that help attackers can help defenders when they are constrained properly. A defender can use AI to summarize long incident timelines, generate Sigma or YARA drafts for review, compare logs against known ATT&CK techniques, translate malware notes, cluster phishing examples, and explain an alert to a junior analyst. Those are useful workflows because they reduce cognitive load without requiring the model to make irreversible decisions.
The strongest defensive use cases keep evidence close to the answer. If an AI assistant says a pattern resembles credential access, it should show the logs, commands, hostnames, accounts, and ATT&CK mapping that led to that interpretation. If it drafts a detection rule, it should include test cases and known blind spots. If it recommends containment, it should name the confidence level and escalation path.
This is where latest AI news can become practical security strategy. Do not copy the headline into a panic memo. Convert it into a control review. Which AI workflows exist. Which ones can call tools. Which logs exist. Which attack scenarios are tested. Which vendor claims are still unsupported. That is the work.
The limits of the current evidence
Anthropic's research is important, but it does not prove that AI agents have replaced human attackers. Public reporting still leaves open questions about scale, sophistication, attribution, and how often model assistance changes outcomes rather than simply speeding up attempts. Security leaders should avoid both complacency and exaggeration.
The evidence is strongest when it describes workflows and observed misuse patterns. It is weaker when people generalize from those patterns into claims about fully autonomous cyber offense. A good security program does not need the stronger claim. Task acceleration is enough to justify better controls.
There is also a measurement problem. If a phishing email is more fluent because a model helped write it, defenders may not know. If exploit code is debugged with AI, the final artifact may look like ordinary code. If a junior attacker uses a model to understand documentation, the observable activity may be identical to human research. That means detection will need to focus on outcomes, accounts, timing, infrastructure, and tool behavior, not just "AI fingerprints."
What to watch next
Watch for three developments. First, expect more AI providers to publish abuse taxonomies and safety enforcement reports. Anthropic's MITRE mapping gives the market a reason to demand more transparent reporting from every major model provider.
Second, expect security tooling to add agent trace analysis. SOC platforms, identity systems, data-loss-prevention tools, and cloud security products will need to ingest AI workflow logs. The question will be whether those logs are detailed enough to investigate incidents.
Third, expect attackers to keep experimenting at the edges of policy. The pressure points are obvious: code generation, vulnerability research, phishing personalization, multilingual operations, and document analysis. Defenders should assume that model-assisted attempts will keep improving even if most are still human-directed.
The detection work that should start now
Security teams can translate Anthropic's research into immediate detection engineering. Start with the parts of the attack chain where model assistance changes observable behavior. Phishing campaigns may show more linguistic variation, better localization, and faster theme rotation. Reconnaissance may show more systematic scraping of documentation, public employee data, and technology clues. Exploit attempts may show rapid changes in scripts after errors. Internal misuse may show unusual prompt patterns around credentials, vulnerability steps, or restricted tools.
That does not mean defenders should look for a magical "AI-generated" signature. The stronger approach is behavioral. Which accounts are asking a model for security-sensitive help. Which agents are retrieving unusual internal documents. Which workflows are generating code that touches authentication, secrets, or deployment. Which prompts request obfuscation, evasion, persistence, or credential harvesting. Which tool calls combine public research with internal access in a way that raises risk.
Teams should also build playbooks for AI-assisted incidents. If a security alert involves an internal agent, the incident handler needs the agent trace, not only the final output. If a vendor reports abuse from an account, the customer needs enough detail to understand whether the activity touched company data. If a prompt-injection attack affects a retrieval system, the team needs to preserve the malicious document, retrieved snippets, model response, and tool-call sequence.
This is where MITRE ATT&CK helps again. Map each AI-assisted behavior to the closest existing technique, then decide what telemetry is missing. If the missing telemetry is model-specific, add it to the AI platform. If the missing telemetry is conventional, fix the security stack. Anthropic's report should not create a separate AI panic lane. It should sharpen the existing detection program.
The best teams will turn that map into quarterly exercises with real prompts, real logs, realistic tool permissions, and post-incident reviews that improve both the AI product and the SOC process.
Bottom line
Anthropic's AI cyber threat map matters because it turns a vague fear into a security architecture discussion. Agentic AI is not only a productivity layer. It is a tool-use layer, and tool use belongs inside threat modeling. The right response is not to ban every AI workflow or trust every vendor assurance. The right response is to log agent activity, restrict tools, test abuse cases, demand evidence, and map model-assisted behavior to security controls the organization already understands.
For readers following Artificial Intelligence News, this is the real signal: AI safety is becoming operational. The winners will not be the teams with the most dramatic demos. They will be the teams that can explain what their agents are allowed to do, prove what they did, and stop them when the answer should be no.